Learning to summarize from human feedback (Paper Explained)

54:39
Rethinking Attention with Performers (Paper Explained)

1:03:18
Extracting Training Data from Large Language Models (Paper Explained)
33:26
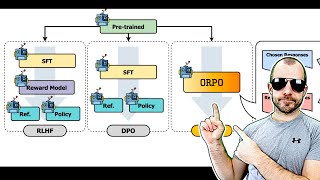
ORPO: Monolithic Preference Optimization without Reference Model (Paper Explained)

12:38
Reinforcement Learning from Human Feedback (RLHF)

31:22
A Equação de Um Trilhão de Dólares

53:02
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters (Paper)

55:01
OpenAI Co-Founder Ilya Sutskever: What's Next for Large Language Models (LLMs)

43:51