Knowledge Distillation: A Good Teacher is Patient and Consistent

13:29
Knowledge Distillation with TAs

19:46
Quantization vs Pruning vs Distillation: Optimizing NNs for Inference
49:30
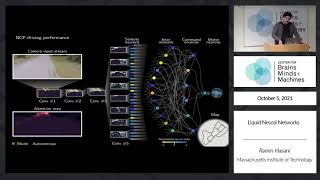
Liquid Neural Networks

24:04
Compressing Large Language Models (LLMs) | w/ Python Code

26:10
Attention in transformers, visually explained | DL6

9:28
How ChatGPT Cheaps Out Over Time

19:05
Distilling the Knowledge in a Neural Network

16:49