Grokking: Generalization beyond Overfitting on small algorithmic datasets (Paper Explained)
48:30
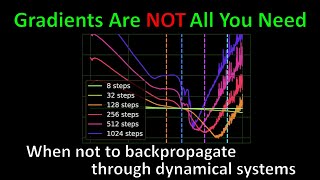
Gradients are Not All You Need (Machine Learning Research Paper Explained)

29:51
New Discovery: LLMs have a Performance Phase
44:20
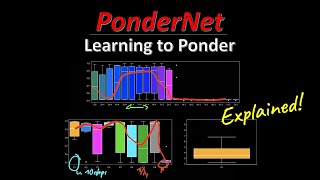
PonderNet: Learning to Ponder (Machine Learning Research Paper Explained)

27:02
Finally: Grokking Solved - It's Not What You Think

37:17
Leave No Context Behind: Efficient Infinite Context Transformers with Infini-attention

20:18
Why Does Diffusion Work Better than Auto-Regression?

54:39
Rethinking Attention with Performers (Paper Explained)

27:48