[GRPO Explained] DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models

25:36
DeepSeek R1 Theory Overview | GRPO + RL + SFT
33:26
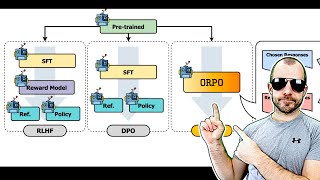
ORPO: Monolithic Preference Optimization without Reference Model (Paper Explained)

57:45
Visualizing transformers and attention | Talk for TNG Big Tech Day '24

37:06
GSM-Symbolic: Understanding the Limitations of Mathematical Reasoning in Large Language Models

24:22
Group Relative Policy Optimization (GRPO) - Formula and Code

18:09
La genialidad del aumento de eficiencia de 57X de DeepSeek [MLA]

37:17
Leave No Context Behind: Efficient Infinite Context Transformers with Infini-attention

29:33