Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention

26:10
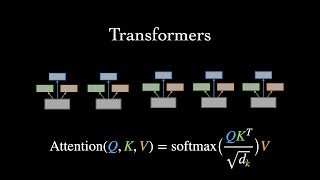
Attention in transformers, visually explained | DL6

48:06
Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention (Paper Explained)

1:12:20
Theoretical Foundations of Graph Neural Networks

31:51
MAMBA from Scratch: Neural Nets Better and Faster than Transformers

50:24
Linformer: Self-Attention with Linear Complexity (Paper Explained)

5:55:34
Sequence Models Complete Course

47:47
MedAI #54: FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness | Tri Dao
16:44