How-to: Cache Model Responses | Langchain | Implementation
30:15
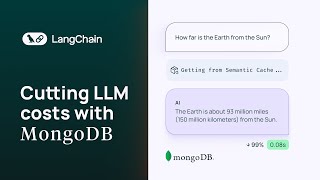
Cutting LLM Costs with MongoDB Semantic Caching

22:44
How-to: Return structured output from LLMs | Langchain | Strategies & Code Implementation

18:26
Stream LLMs with LangChain + Streamlit | Tutorial

27:54
Memory Management for Chatbots using Langchain | OpenAI | Gradio

20:36
Florence 2 Vision Language Model - Intro, Demo and Inference Code

12:58
Slash API Costs: Mastering Caching for LLM Applications

20:28
Build an SQL Agent with Llama 3 | Langchain | Ollama

32:30