25. Stochastic Gradient Descent

53:17
26. Structure of Neural Nets for Deep Learning

23:54
Gradiente descendente, passo a passo

49:02
23. Accelerating Gradient Descent (Use Momentum)

27:49
The Stochastic Gradient Descent Algorithm

1:18:19
Lecture 15 - Kernel Methods
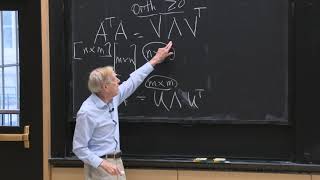
53:34
6. Singular Value Decomposition (SVD)

20:33
Gradient descent, how neural networks learn | DL2

1:09:26