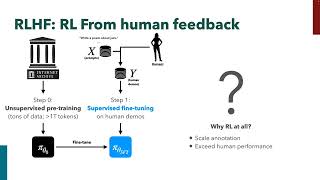
Reinforcement Learning with Human Feedback - How to train and fine-tune Transformer Models

38:24
Proximal Policy Optimization (PPO) - How to train Large Language Models

21:15
Direct Preference Optimization (DPO) - How to fine-tune LLMs directly without reinforcement learning

44:26
What are Transformer Models and how do they work?
36:26
A friendly introduction to deep reinforcement learning, Q-networks and policy gradients
54:29
CS 285: Eric Mitchell: Reinforcement Learning from Human Feedback: Algorithms & Applications

22:43
How might LLMs store facts | DL7

58:06
Stanford Webinar - Large Language Models Get the Hype, but Compound Systems Are the Future of AI

1:21:43