OMPar: Automatic Parallelization with AI-Driven Source-to-Source Compilation
21:46
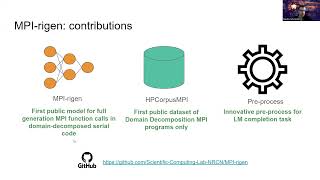
MPIrigen: MPI Code Generation through Domain-Specific Language Models (AI4Sys - HPDC'24)

1:43:09
Advances in GPU offloading with OpenMP: From trivial to perfect

26:26
RAG - Bases de données vectorielles pour RAG

31:34
Llama 3.3, pourquoi et comment mettre ce LLM en production + déploiement de modèles non censurés

22:01
Heroes: Lightweight Federated Learning with Neural Composition and Adaptive Local Update in ...

1:46:41
Shared-Memory parallelism: CPUs, GPUs, and in-between - Lecture 9 (Yehonatan Fridman)

54:18
L'IA à la pointe : la recherche en IA de Qualcomm au NeurIPS 2024 avec Arash Behboodi - 711

29:28