Master Reading Spark Query Plans

34:14
Master Reading Spark DAGs

19:03
Shuffle Partition Spark Optimization: 10x Faster!
23:09
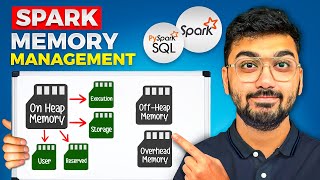
Apache Spark Memory Management

20:37
Broadcast Joins & AQE (Adaptive Query Execution)

27:25
Credit Risk Modeling: PD Model with Scorecard | IV, VIF, Correlation & Model Validation Explained

13:51
Apache Iceberg™ | What It Is and Why Everyone’s Talking About It

22:18
How Partitioning Works In Apache Spark?

30:19