RWKV: Reinventing RNNs for the Transformer Era (Paper Explained)

32:27
Efficient Streaming Language Models with Attention Sinks (Paper Explained)

40:40
Mamba: Linear-Time Sequence Modeling with Selective State Spaces (Paper Explained)
29:29
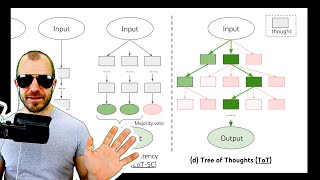
Tree of Thoughts: Deliberate Problem Solving with Large Language Models (Full Paper Review)

18:41
¿Qué es un TRANSFORMER? La Red Neuronal que lo cambió TODO!

27:14
Transformers (how LLMs work) explained visually | DL5

37:17
Leave No Context Behind: Efficient Infinite Context Transformers with Infini-attention

1:09:37
ChatGPT Prompting vs RAG vs fine tuning: Aprovecha la IA al máximo | #laFunción 9x18

26:10