An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale (Paper Explained)

30:49
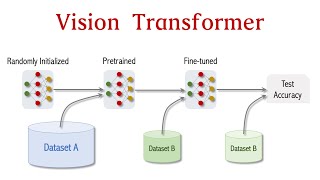
Vision Transformer Basics

59:33
LambdaNetworks: Modeling long-range Interactions without Attention (Paper Explained)

36:15
2024 12 24 15 43 12
14:47
Vision Transformer for Image Classification

48:07
OpenAI CLIP: ConnectingText and Images (Paper Explained)

31:21
[Classic] Deep Residual Learning for Image Recognition (Paper Explained)

27:14
Transformers (how LLMs work) explained visually | DL5

24:57